JPA
in Spring on Jpa, Sql
JPA란?
- Java Persistence API
- 자바 진영의 ORM 기술 표준
📌 ORM?
- Object-relational mapping(객체 관계 매핑)
- 객체는 객체대로 설계
- 관계형 데이터베이스는 관계형 데이터베이스대로 설계
- ORM 프레임워크가 중간에서 매핑
- 대중적인 언어에는 대부분 ORM 기술이 존재
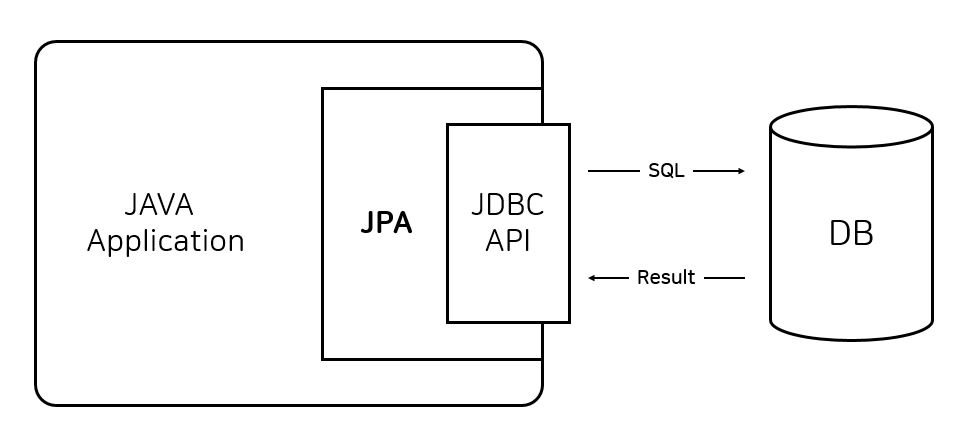
JPA는 애플리케이션과 JDBC 사이에서 동작
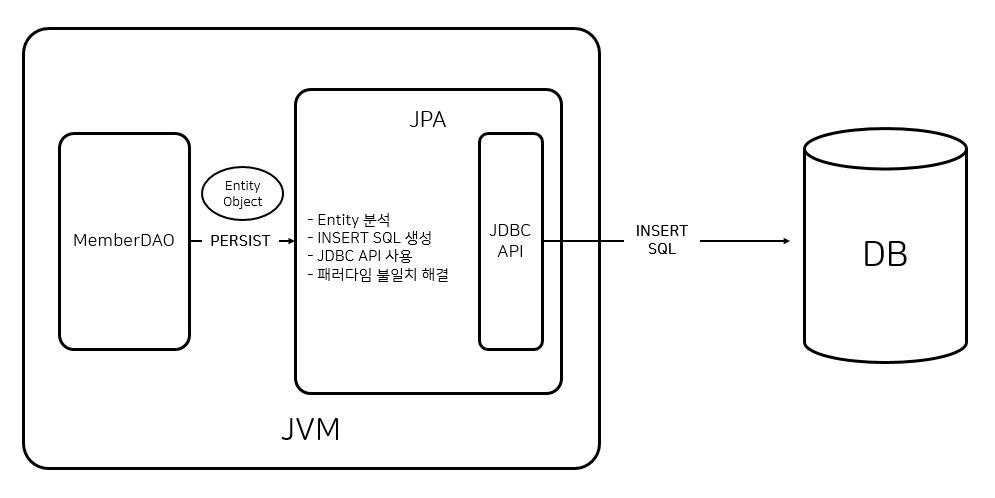
JPA 동작 - 저장
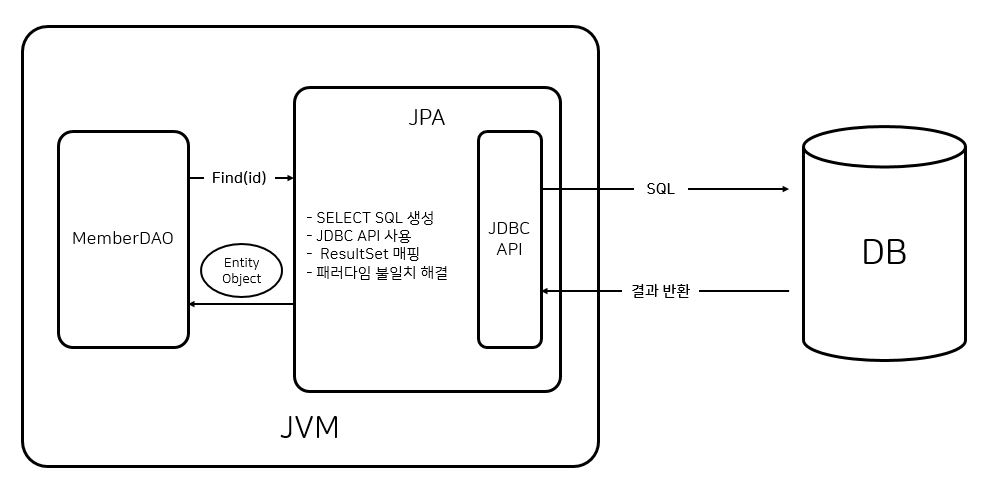
JPA 동작 - 조회
📌 SQL 중심적인 개발의 문제점
- CRUD 무한반복..😱
- SQL에 의존적인 개발을 피하기 어렵다.
- 관계형 데이터베이스와 객체의 페러다임 불일치
➜ 관계형 데이터베이스는 데이터를 보관하는게 목표 객체는 캡슐화가 목표! - 처음 실행하는 SQL에 따라 탐색 범위 결정
➜ 엔티티 신뢰 문제가 발생한다! - 모든 객체를 미리 로딩할 수 없다.
➜ 상황에 따라 동일한 조회 메소드 여러번 생성 - 객체답게 모델링 할수록 매핑 작업만 늘어난다.😟
📌 객체와 관계형 데이터베이스의 차이
- 상속
- 연관관계
- 데이터 타입
- 데이터 식별 방법
상속

- Album 저장
- 객체 분해
- INSERT INTO ITEM …
- INSERT INTO ALBUM …
➜ 두번 저장해야 한다!!❓ Album을 자바 컬렉션에 저장한다면?
list.add(album);코드 한줄로 끝!!
- Album 조회
- 각각의 테이블에 따른 조인 SQL 작성
- 각각의 객체 생성
- 기타 등등…😵
- 그래서 DB에 저장할 객체에는 상속 관계 안쓴다!
❓ Album을 자바 컬렉션에 저장한다면?
Album album = list.get(albumId);
Item item = list.get(albumId);부모 타입 조회해서 다형성 활용할 수도 있음!!
연관관계

- 객체
- 참조 사용
- member.getTeam()
- Member ➜ Team은 가능하지만 Team ➜ Member는 불가능!! (단방향)
- 테이블
- 외래 키 사용
- JOIN ON M.TEAM_ID = T.TEAM_ID
- Member ➜ Team AND Team ➜ Member 둘 다 자유롭게 가능!! (양방향)
비교하기
SQL 조회String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; //다르다.
❓ 왜 다를까!?class MemberDAO {
public Member getMember(String memberId) {
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?";
...
//JDBC API, SQL 실행
return new Member(...);
}
}
➜ DAO에서 객체를 매번 생성하기 때문에!!
자바 컬렉션에서 조회String memberId = "100";
Member member1 = list.get(memberId);
Member member2 = list.get(memberId);
member1 == member2; //같다.
📌 JPA 사용 이유
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 저장: jpa.persist(member)
- 조회: Member member = jpa.find(memberId)
- 수정: member.setName(“변경할 이름”)
- 삭제: jpa.remove(member)
- 유지보수
- 기존: 필드 변경시 모든 SQL 수정
- JPA: 필드만 추가하면 됨, SQL은 JPA가 처리
- 패러다임의 불일치 해결
- 성능
- 데이터 접근 추상화와 벤더 독립성
- 표준
📌 패러다임의 불일치 해결
JPA 상속 - 저장
실제 코드jpa.persist(album);
JPA 처리 코드INSERT INTO ITEM ...
INSERT INTO ALBUM ...
JPA 상속 - 조회
실제 코드Album album = jpa.find(Album.class, albumId);
JPA 처리 코드SELECT I.*, A.*
FROM ITEM I
JOIN ALBUM A ON I.ITEM_ID = A.ITEM_ID
JPA 연관관계, 객체 그래프 탐색
연관관계 저장member.setTeam(team);
jpa.persist(member);
객체 그래프 탐색Member member = jpa.find(Member.class, memberId);
Team team = member.getTeam();
JPA 비교하기
String memberId = "100";
Member member1 = jpa.find(Member.class, memberId);
Member member2 = jpa.find(Member.class, memberId);
member1 == member2; //같다.📢 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장합니다.
📌 JPA 성능
1차 캐시와 동일성 보장
- 같은 트랜잭션 안에서는 같은 엔티티를 반환
약간의 조회 성능 향상
➜ SQL을 한번만 실행합니다. - DB Isolation Level이 Read Commit이어도 애플리케이션에서 Repeatable Read 보장
트랜잭션을 지원하는 쓰기 지연
JDBC BATCH SQL 기능을 사용해서 한번에 SQL을 전송합니다.transaction.begin();
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
transaction.commit();
지연 로딩과 즉시 로딩
- 지연 로딩: 객체가 실제 사용될 때 로딩
- 단점 : 네트워크를 두번 탄다!
- 즉시 로딩: JOIN SQL로 한번에 연관된 객체까지 미리 조회
➜ 자주 같이 쓰면 즉시 로딩, 아니면 지연 로딩 옵션으로 선택할 수 있다!!
